
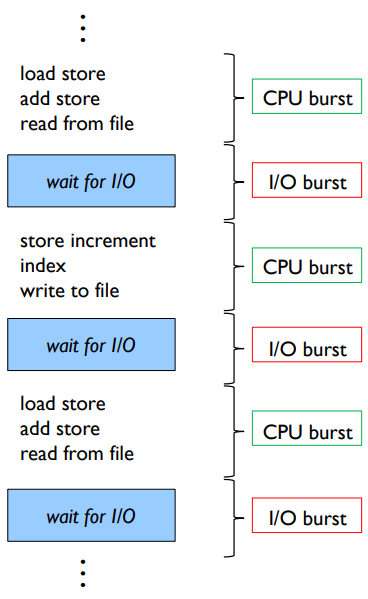
CPU-I/O 버스트 주기
CPU 버스트와 I/O 버스트의 교대 시퀀스
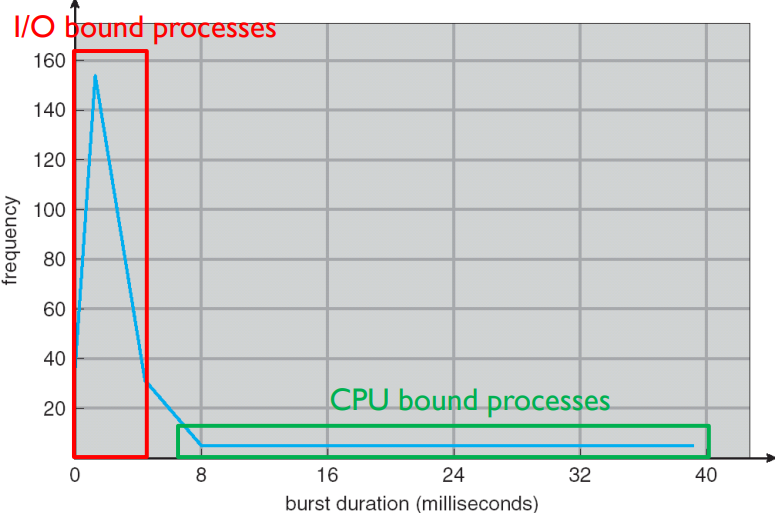
CPU 버스트 시간 히스토그램
CPU 스케줄러
CPU 스케줄러
- 실행할 준비가 된 프로세스 중에서 프로세스를 선택
CPU 스케줄링 결정은 다음과 같은 경우에 발생할 수 있다.
- 프로세스가 실행 상태(running)에서 대기 상태(waiting)로 전환(예: I/O 요청)
- 프로세스가 실행 상태(running)에서 준비 상태(ready)로 전환(예: 타임 슬라이스 만료)
- 프로세스가 대기(waiting)에서 준비 상태(ready)로 전환(예: I/O 완료)
- 프로세스가 종료
- → 1, 4 스케줄링은 비선점적(non-preemptive)
- → 2, 3 스케줄링은 선점적(preemptive)
디스패처(Dispatcher)
- CPU 스케줄러가 선택한 프로세스에 CPU 제어 권한을 부여
컨텍스트를 전환
사용자 모드로 전환
선택한 프로세스를 다시 시작하기 위해 적절한 위치로 이동 - 디스패치 대기 시간
디스패처가 한 프로세스를 중지하고 다른 프로세스를 시작하는 데 걸리는 시간
스케줄링 오버헤드
스케줄링 기준
CPU 사용률(CPU utilization)
- CPU를 가능한 한 바쁘게(busy) 유지 (0% ~ 100%)
처리량(Throughput)
- 시간 단위당 완료된 프로세스 수
처리 시간(Turnaround time)
- 요청 제출부터 완료까지의 시간
대기 시간(Waiting time)
- 프로세스가 준비 큐에서 대기한 시간의 합
응답 시간(Response time)
- 요청 제출부터 첫 번째 응답이 생성까지의 시간
스케줄링 알고리즘의 목표
- CPU 사용율 극대화
- 처리량 극대화
- 시간처리 최소화
- 대기시간 최소화
- 응답시간 최소화
응답 시간의 평균보다 분산을 최소화하는 것이 더 중요할 수 있습니다.
예) 대화형 시스템
스케줄링 알고리즘
FCFS (First-Come First-Served)
SJF (Shortest-Job-First)
SRTF (Shortest-Remaining-Time-First)
Priority Scheduling
RR (Round Robin)
Multilevel Queue
Multilevel Feedback Queue
...
First-Come First-Served (FCFS)
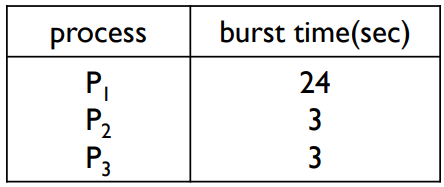
프로세스 세트
스케줄링 Gantt 차트

- 대기시간(Waiting time) : P1 = 0, P2 = 24, P3 = 27
- 평균 대기시간(Average waiting time) : (0 + 24 + 27)/3 = 17
- FCFS는 비선점적

- 대기시간(Waiting time) : P1 = 6, P2 = 0, P3 = 3
- 평균 대기시간(Average waiting time) : (6 + 0 + 3)/3 = 3
- → 이전의 경우보다 훨씬 낫다.
Shortest-Job-First (SJF)
CPU 버스트가 가장 작은 프로세스에 CPU를 할당
두 가지 버전
- 비선점적
CPU가 프로세스에 할당되면 CPU를 선점할 수 없다. - 선점적
새 프로세스가 현재 실행 중인 프로세스의 남은 시간보다 짧은 CPU 버스트 길이로 도착하는 경우 선점한다.
SRTF(Shortest-Remaining-Time-First)
SJF는 평균 대기 시간 측면에서 최적
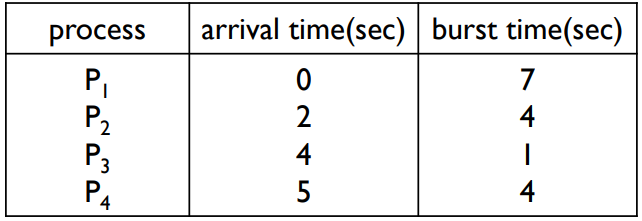
비선점적 SJF 스케줄링 Gantt 차트

- 대기시간(Waiting time) : P1 = 0, P2 = 6, P3 = 3, P4 = 7
- 평균 대기시간(Average waiting time) : (0 + 6 + 3 + 7)/4 = 4
선점적 SJF(최단 남은 시간 우선) 스케줄링 Gantt 차트

- 대기시간(Waiting time) : P1 = 9, P2 = 1, P3 = 0, P4 = 2
- 평균 대기시간(Average waiting time) : (9 + 1 + 0 + 2)/4 = 3
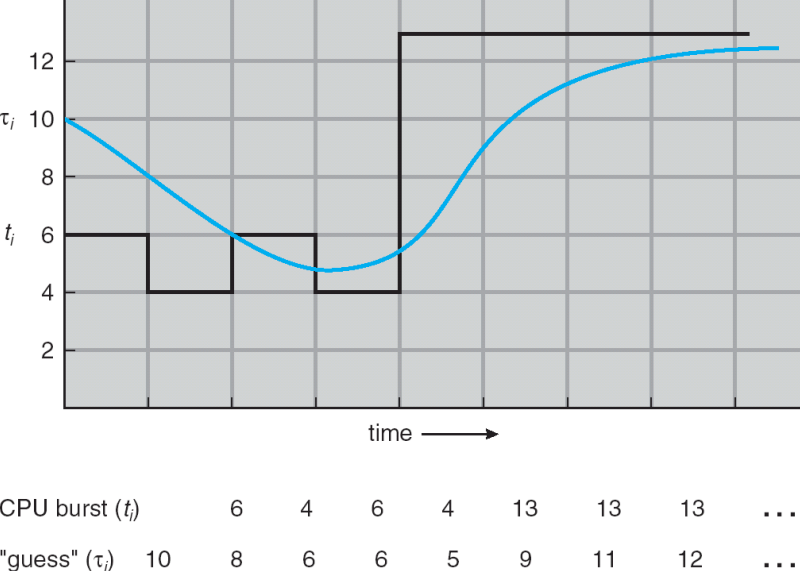
다음 CPU 버스트 시간의 길이를 결정해야 한다.
이전 CPU 버스트 시간의 길이를 사용한 추정(지수 평균)
- tn = n번째 CPU 버스트의 실제 길이
- τ(n+1) = 다음 CPU 버스트에 대한 예측 값
- α, 0 ≤ α ≤ 1 → 적응의 속도
- 정의: γ(n+1) = αtn + (1-α)γ(n)
- 일반적으로 α는 1/2로 설정된다.
다음 CPU 버스트 시간
- τ(n+1) = αtn + (1-α)τ(n)
- α = 0
τ(n+1) = τ(n)
최근 내역은 영향을 미치지 않는다. - α = 1
τ(n+1) = t(n)
가장 최근의 CPU 버스트만 중요하다. - 공식을 확장하면
τ(n+1) = α t(n) + (1-α)α tn-1 + ...
+ (1-α)^j α t(n-j) + ...
+ (1-α)^(n+1) τ0 - α 및 (1 - α)가 모두 1보다 작거나 같으므로 각 연속된 항은 이전 항보다 가중치가 작다.
다음 CPU 버스트 시간의 길이 예측
우선 순위 스케줄링(Priority Scheduling)
우선 순위 번호(정수)는 각 프로세스와 연결된다.
CPU는 우선 순위가 가장 높은 프로세스에 할당
- 가장 작은 정수 = 가장 높은 우선순위
SJF는 우선순위 스케줄링
- 다음 CPU 버스트 시간을 예측하는 것이 우선
문제
- starvation(기아) : 우선순위가 낮은 프로세스는 절대 실행되지 않는다.
해결책
- Aging : 시간이 경과함에 따라 프로세스의 우선순위를 높인다.
Round Robin (RR)
각 프로세스는 CPU 시간의 작은 단위를 얻는다.
- 시간 퀀텀 또는 시간 슬라이스
일반적으로 10-100밀리초 - 이 시간이 경과하면,
프로세스가 선점되어 준비 큐의 끝에 추가된다.
준비 큐 & 시간 퀀텀의 n개의 프로세스가 q이면,
- 각 프로세스는 한번에 최대 q 시간 단위로 CPU 시간의 1/n을 가져온다.
- (n-1)q 시간 단위 이상 대기하는 프로세스는 없다.
성능
- q가 크다. → FCFS
- q가 작다. → 컨텍스트 전환 오버헤드가 너무 높다.
시간 퀀텀이 2인 라운드로빈
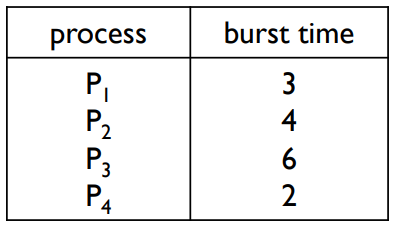
스케줄링 gantt 차트

응답시간(Response time) : P1 = 0, P2 = 2, P3 = 4, P4 = 6
평균 응답시간(Average response time) : (0 + 2 + 4 + 6)/4 = 3
→ 일반적으로 평균 처리 시간은 SJF보다 높지만 평균 응답시간은 낮다.
시간 퀀텀 및 컨텍스트 전환 시간
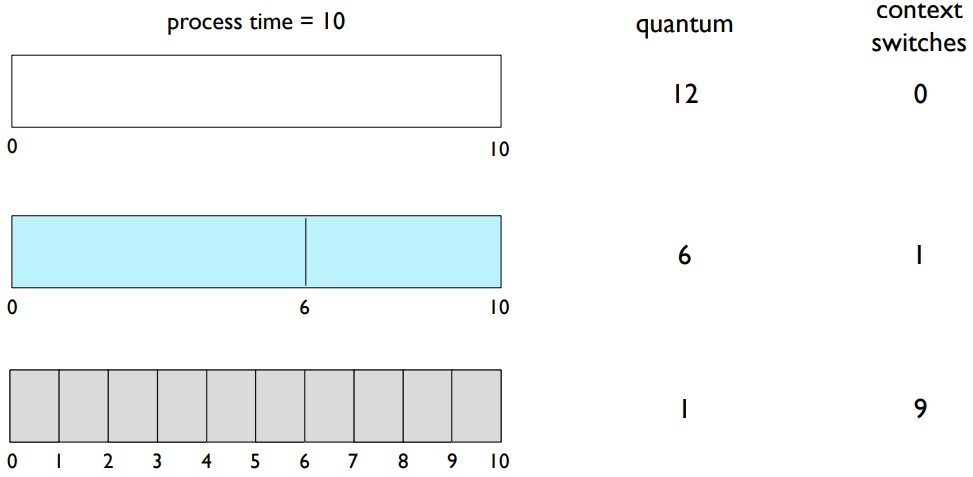
처리 시간은 시간 퀀텀에 따라 다르다.

Multilevel Queue
준비 대기열(queue)은 별도의 대기열로 분할
- 포그라운드 대기열(대화형 프로세스용)
- 백그라운드 대기열(배치 프로세스용)
각 대기열에는 자체 스케줄링 알고리즘이 있다.
- 포그라운드 큐 - RR
- 백그라운드 큐 - FCFS
대기열 간에 스케줄링을 수행해야 한다.
- 고정 우선순위 스케줄링
서비스 프로세스를 포그라운드 대기열에 먼저 배치
starvation(기아)의 가능성. - 시간 슬라이스
각 대기열은 일정량의 CPU 시간을 얻는다.
포그라운드 대기열에 있는 프로세스의 경우 80%
백그라운드 대기열에 있는 프로세스의 경우 20%
다단계 큐잉 예제
Multilevel Feedback Queues
프로세스는 다양한 대기열 사이를 이동할 수 있다.
multilevel-feedback-queue 스케줄러의 매개변수
- 대기열 수
- 각 대기열에 대한 스케줄링 알고리즘
- 프로세스를 업그레이드할 때를 결정하는 데 사용되는 방법
- 프로세스를 강등할 때를 결정하는 데 사용되는 방법
- 프로세스가 서비스를 필요로 할 때 프로세스가 들어갈 대기열을 결정하는 데 사용되는 방법
멀티프로세서 스케줄링
- 단일 프로세서 스케줄링보다 더 복잡
두 가지 유형의 스케줄링
- Asymmetric multiprocessing(비대칭 멀티프로세싱)
마스터 프로세서는 스케줄링 결정을 수행하고, 다른 프로세서는 사용자 코드를 실행 - Symmetric Multiprocessing(SMP; 대칭 멀티프로세싱)
각 프로세서는 자체적으로 스케줄링 결정을 내린다.
현재 가장 일반적
다중 프로세서 스케줄링에 대한 새로운 문제
- 프로세서 선호도(Processor affinity)
동일한 프로세서에서 실행되는 프로세스를 유지 - 부하 분산(Load balancing)
워크로드를 모든 프로세서에 고르게 분산
마이그레이션 밀어넣기, 마이그레이션 꺼내기
SMP인 경우 효율성을 위해 모든 CPU 로드 상태를 유지
부하 분산(load balancing)
- 작업량을 균등하게 분산시키는 시도
푸시 마이그레이션
- 주기적인 작업은 각 프로세서의 부하를 확인하고, 발견되면 과부하된 CPU에서 다른 CPU로 작업을 푸시
풀 마이그레이션
- 쉬고있는 프로세서가 바쁜 프로세서에서 대기 중인 작업을 꺼낸다.
리눅스 스케줄링
타임슬라이스로 타임셰어링
- -타임슬라이스가 있는 프로세스만 실행
-타이머 인터럽트 발생 시 타임슬라이스가 차감
-타입슬라이스 = 0이면 다른 프로세스가 선택
-모든 프로세스가 타임슬라이스 = 0이면 재계산 수행
실시간 우선순위
- 소프트 실시간Soft real-time
- 우선 순위가 가장 높은 프로세스가 항상 먼저 실행
→ 리눅스는 타임슬라이스로 우선 순위가 가장 높은 프로세스를 스케줄링
우선 순위가 높은 프로세스에는 더 긴 타임 슬라이스가 주어진다.

우선 순위에 따라 인덱싱된 작업 목록

알고리즘 평가
결정론적 모델링
- 특정 사전 정의된 작업량를 처리한 후
- 해당 작업량에 대한 각 알고리즘의 성능을 정의
- 예: 일련의 프로세스가 지정된 경우 Gantt Chart를 사용한 SJF

- 간단하고 빠르다.
- 알고리즘을 설명하고 예제를 제공하는 데 유용
대기열 모델
- 수학적 공식 사용
- 간단한 큐잉 네트워크 모델
- 도착 요금과 서비스 요금을 고려할 때,
사용률, 평균 대기열 길이,평균 대기 시간을 도출 가능 - 일부 평가에서 제한적으로 사용
시뮬레이션
- 컴퓨터 시스템 모델을 프로그래밍
데이터 구조는 시스템의 주요 구성 요소를 나타낸다.
예: 시계 변수 - 난수 발생기가 필요
프로세스 수, CPU 버스트 시간, 도착, 출발 등
균일, 지수, 포아송 등. - 많은 공간, 시간 필요
시뮬레이터의 설계, 코딩, 디버깅은 시간이 많이 걸린다.
많은 스토리지 공간과 시간이 필요
구현
- 알고리즘을 완전히 정확하게 평가할 수 있는 유일한 방법
- 매우 어렵다.
알고리즘 코딩
운영 체제 수정
요약
- CPU 스케줄러
실행할 준비가 된 프로세스 중에서 프로세스를 선택 - 스케줄링 알고리즘의 목표
CPU 사용률, 처리량을 최대화
처리 시간, 대기 시간, 응답 시간을 최소화 - SJF(Shortest Job First)
CPU 버스트 시간이 가장 짧은 프로세스에 CPU를 할당 - Round Robin
각 프로세스는 시간 퀀텀이라는 작은 CPU 시간 단위 - Multilevel Feedback Queues
프로세스는 다양한 대기열 사이를 이동
'운영체제' 카테고리의 다른 글
| [OS] 교착상태(Deadlocks) (0) | 2023.04.17 |
|---|---|
| [OS] 동기화 도구 (0) | 2023.04.03 |
| [OS] 쓰레드와 프로세스 (0) | 2023.03.20 |
| [OS] 프로세스 (0) | 2023.03.13 |
| [OS] 서비스, 시스템 콜, 구조, 부팅 과정 (0) | 2023.03.09 |
CPU-I/O 버스트 주기
CPU 버스트와 I/O 버스트의 교대 시퀀스
CPU 버스트 시간 히스토그램
CPU 스케줄러
CPU 스케줄러
- 실행할 준비가 된 프로세스 중에서 프로세스를 선택
CPU 스케줄링 결정은 다음과 같은 경우에 발생할 수 있다.
- 프로세스가 실행 상태(running)에서 대기 상태(waiting)로 전환(예: I/O 요청)
- 프로세스가 실행 상태(running)에서 준비 상태(ready)로 전환(예: 타임 슬라이스 만료)
- 프로세스가 대기(waiting)에서 준비 상태(ready)로 전환(예: I/O 완료)
- 프로세스가 종료
- → 1, 4 스케줄링은 비선점적(non-preemptive)
- → 2, 3 스케줄링은 선점적(preemptive)
디스패처(Dispatcher)
- CPU 스케줄러가 선택한 프로세스에 CPU 제어 권한을 부여
컨텍스트를 전환
사용자 모드로 전환
선택한 프로세스를 다시 시작하기 위해 적절한 위치로 이동 - 디스패치 대기 시간
디스패처가 한 프로세스를 중지하고 다른 프로세스를 시작하는 데 걸리는 시간
스케줄링 오버헤드
스케줄링 기준
CPU 사용률(CPU utilization)
- CPU를 가능한 한 바쁘게(busy) 유지 (0% ~ 100%)
처리량(Throughput)
- 시간 단위당 완료된 프로세스 수
처리 시간(Turnaround time)
- 요청 제출부터 완료까지의 시간
대기 시간(Waiting time)
- 프로세스가 준비 큐에서 대기한 시간의 합
응답 시간(Response time)
- 요청 제출부터 첫 번째 응답이 생성까지의 시간
스케줄링 알고리즘의 목표
- CPU 사용율 극대화
- 처리량 극대화
- 시간처리 최소화
- 대기시간 최소화
- 응답시간 최소화
응답 시간의 평균보다 분산을 최소화하는 것이 더 중요할 수 있습니다.
예) 대화형 시스템
스케줄링 알고리즘
FCFS (First-Come First-Served)
SJF (Shortest-Job-First)
SRTF (Shortest-Remaining-Time-First)
Priority Scheduling
RR (Round Robin)
Multilevel Queue
Multilevel Feedback Queue
...
First-Come First-Served (FCFS)
프로세스 세트
스케줄링 Gantt 차트
- 대기시간(Waiting time) : P1 = 0, P2 = 24, P3 = 27
- 평균 대기시간(Average waiting time) : (0 + 24 + 27)/3 = 17
- FCFS는 비선점적
- 대기시간(Waiting time) : P1 = 6, P2 = 0, P3 = 3
- 평균 대기시간(Average waiting time) : (6 + 0 + 3)/3 = 3
- → 이전의 경우보다 훨씬 낫다.
Shortest-Job-First (SJF)
CPU 버스트가 가장 작은 프로세스에 CPU를 할당
두 가지 버전
- 비선점적
CPU가 프로세스에 할당되면 CPU를 선점할 수 없다. - 선점적
새 프로세스가 현재 실행 중인 프로세스의 남은 시간보다 짧은 CPU 버스트 길이로 도착하는 경우 선점한다.
SRTF(Shortest-Remaining-Time-First)
SJF는 평균 대기 시간 측면에서 최적
비선점적 SJF 스케줄링 Gantt 차트
- 대기시간(Waiting time) : P1 = 0, P2 = 6, P3 = 3, P4 = 7
- 평균 대기시간(Average waiting time) : (0 + 6 + 3 + 7)/4 = 4
선점적 SJF(최단 남은 시간 우선) 스케줄링 Gantt 차트
- 대기시간(Waiting time) : P1 = 9, P2 = 1, P3 = 0, P4 = 2
- 평균 대기시간(Average waiting time) : (9 + 1 + 0 + 2)/4 = 3
다음 CPU 버스트 시간의 길이를 결정해야 한다.
이전 CPU 버스트 시간의 길이를 사용한 추정(지수 평균)
- tn = n번째 CPU 버스트의 실제 길이
- τ(n+1) = 다음 CPU 버스트에 대한 예측 값
- α, 0 ≤ α ≤ 1 → 적응의 속도
- 정의: γ(n+1) = αtn + (1-α)γ(n)
- 일반적으로 α는 1/2로 설정된다.
다음 CPU 버스트 시간
- τ(n+1) = αtn + (1-α)τ(n)
- α = 0
τ(n+1) = τ(n)
최근 내역은 영향을 미치지 않는다. - α = 1
τ(n+1) = t(n)
가장 최근의 CPU 버스트만 중요하다. - 공식을 확장하면
τ(n+1) = α t(n) + (1-α)α tn-1 + ...
+ (1-α)^j α t(n-j) + ...
+ (1-α)^(n+1) τ0 - α 및 (1 - α)가 모두 1보다 작거나 같으므로 각 연속된 항은 이전 항보다 가중치가 작다.
다음 CPU 버스트 시간의 길이 예측
우선 순위 스케줄링(Priority Scheduling)
우선 순위 번호(정수)는 각 프로세스와 연결된다.
CPU는 우선 순위가 가장 높은 프로세스에 할당
- 가장 작은 정수 = 가장 높은 우선순위
SJF는 우선순위 스케줄링
- 다음 CPU 버스트 시간을 예측하는 것이 우선
문제
- starvation(기아) : 우선순위가 낮은 프로세스는 절대 실행되지 않는다.
해결책
- Aging : 시간이 경과함에 따라 프로세스의 우선순위를 높인다.
Round Robin (RR)
각 프로세스는 CPU 시간의 작은 단위를 얻는다.
- 시간 퀀텀 또는 시간 슬라이스
일반적으로 10-100밀리초 - 이 시간이 경과하면,
프로세스가 선점되어 준비 큐의 끝에 추가된다.
준비 큐 & 시간 퀀텀의 n개의 프로세스가 q이면,
- 각 프로세스는 한번에 최대 q 시간 단위로 CPU 시간의 1/n을 가져온다.
- (n-1)q 시간 단위 이상 대기하는 프로세스는 없다.
성능
- q가 크다. → FCFS
- q가 작다. → 컨텍스트 전환 오버헤드가 너무 높다.
시간 퀀텀이 2인 라운드로빈
스케줄링 gantt 차트
응답시간(Response time) : P1 = 0, P2 = 2, P3 = 4, P4 = 6
평균 응답시간(Average response time) : (0 + 2 + 4 + 6)/4 = 3
→ 일반적으로 평균 처리 시간은 SJF보다 높지만 평균 응답시간은 낮다.
시간 퀀텀 및 컨텍스트 전환 시간
처리 시간은 시간 퀀텀에 따라 다르다.
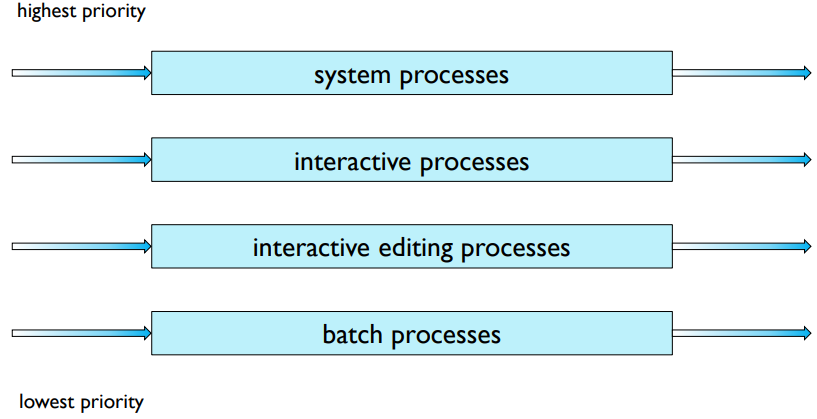
Multilevel Queue
준비 대기열(queue)은 별도의 대기열로 분할
- 포그라운드 대기열(대화형 프로세스용)
- 백그라운드 대기열(배치 프로세스용)
각 대기열에는 자체 스케줄링 알고리즘이 있다.
- 포그라운드 큐 - RR
- 백그라운드 큐 - FCFS
대기열 간에 스케줄링을 수행해야 한다.
- 고정 우선순위 스케줄링
서비스 프로세스를 포그라운드 대기열에 먼저 배치
starvation(기아)의 가능성. - 시간 슬라이스
각 대기열은 일정량의 CPU 시간을 얻는다.
포그라운드 대기열에 있는 프로세스의 경우 80%
백그라운드 대기열에 있는 프로세스의 경우 20%
다단계 큐잉 예제
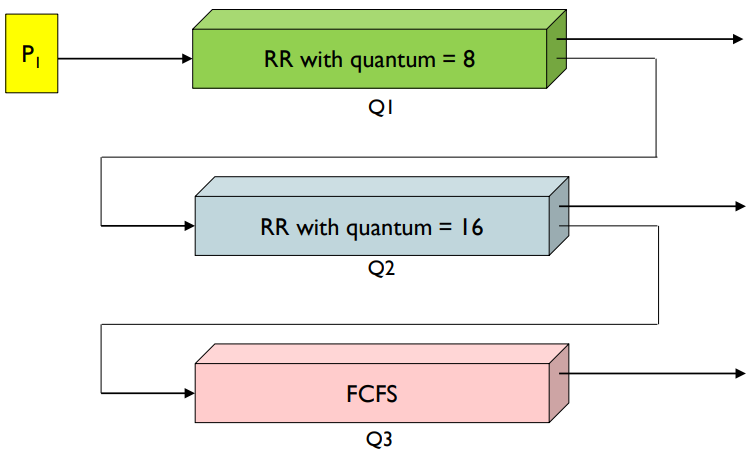
Multilevel Feedback Queues
프로세스는 다양한 대기열 사이를 이동할 수 있다.
multilevel-feedback-queue 스케줄러의 매개변수
- 대기열 수
- 각 대기열에 대한 스케줄링 알고리즘
- 프로세스를 업그레이드할 때를 결정하는 데 사용되는 방법
- 프로세스를 강등할 때를 결정하는 데 사용되는 방법
- 프로세스가 서비스를 필요로 할 때 프로세스가 들어갈 대기열을 결정하는 데 사용되는 방법
멀티프로세서 스케줄링
- 단일 프로세서 스케줄링보다 더 복잡
두 가지 유형의 스케줄링
- Asymmetric multiprocessing(비대칭 멀티프로세싱)
마스터 프로세서는 스케줄링 결정을 수행하고, 다른 프로세서는 사용자 코드를 실행 - Symmetric Multiprocessing(SMP; 대칭 멀티프로세싱)
각 프로세서는 자체적으로 스케줄링 결정을 내린다.
현재 가장 일반적
다중 프로세서 스케줄링에 대한 새로운 문제
- 프로세서 선호도(Processor affinity)
동일한 프로세서에서 실행되는 프로세스를 유지 - 부하 분산(Load balancing)
워크로드를 모든 프로세서에 고르게 분산
마이그레이션 밀어넣기, 마이그레이션 꺼내기
SMP인 경우 효율성을 위해 모든 CPU 로드 상태를 유지
부하 분산(load balancing)
- 작업량을 균등하게 분산시키는 시도
푸시 마이그레이션
- 주기적인 작업은 각 프로세서의 부하를 확인하고, 발견되면 과부하된 CPU에서 다른 CPU로 작업을 푸시
풀 마이그레이션
- 쉬고있는 프로세서가 바쁜 프로세서에서 대기 중인 작업을 꺼낸다.
리눅스 스케줄링
타임슬라이스로 타임셰어링
- -타임슬라이스가 있는 프로세스만 실행
-타이머 인터럽트 발생 시 타임슬라이스가 차감
-타입슬라이스 = 0이면 다른 프로세스가 선택
-모든 프로세스가 타임슬라이스 = 0이면 재계산 수행
실시간 우선순위
- 소프트 실시간Soft real-time
- 우선 순위가 가장 높은 프로세스가 항상 먼저 실행
→ 리눅스는 타임슬라이스로 우선 순위가 가장 높은 프로세스를 스케줄링
우선 순위가 높은 프로세스에는 더 긴 타임 슬라이스가 주어진다.
우선 순위에 따라 인덱싱된 작업 목록
알고리즘 평가
결정론적 모델링
- 특정 사전 정의된 작업량를 처리한 후
- 해당 작업량에 대한 각 알고리즘의 성능을 정의
- 예: 일련의 프로세스가 지정된 경우 Gantt Chart를 사용한 SJF
- 간단하고 빠르다.
- 알고리즘을 설명하고 예제를 제공하는 데 유용
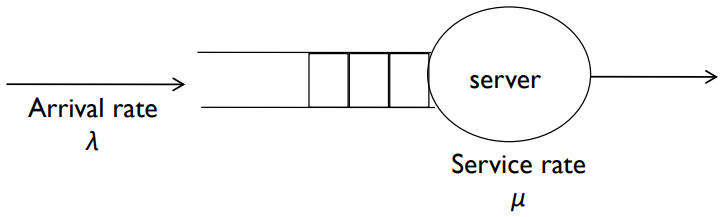
대기열 모델
- 수학적 공식 사용
- 간단한 큐잉 네트워크 모델
- 도착 요금과 서비스 요금을 고려할 때,
사용률, 평균 대기열 길이,평균 대기 시간을 도출 가능 - 일부 평가에서 제한적으로 사용
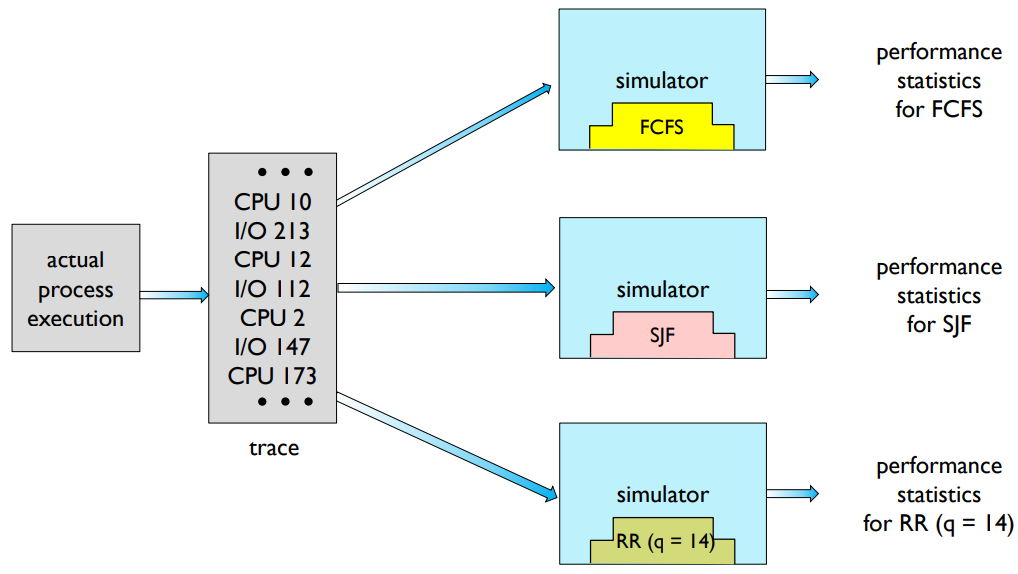
시뮬레이션
- 컴퓨터 시스템 모델을 프로그래밍
데이터 구조는 시스템의 주요 구성 요소를 나타낸다.
예: 시계 변수 - 난수 발생기가 필요
프로세스 수, CPU 버스트 시간, 도착, 출발 등
균일, 지수, 포아송 등. - 많은 공간, 시간 필요
시뮬레이터의 설계, 코딩, 디버깅은 시간이 많이 걸린다.
많은 스토리지 공간과 시간이 필요
구현
- 알고리즘을 완전히 정확하게 평가할 수 있는 유일한 방법
- 매우 어렵다.
알고리즘 코딩
운영 체제 수정
요약
- CPU 스케줄러
실행할 준비가 된 프로세스 중에서 프로세스를 선택 - 스케줄링 알고리즘의 목표
CPU 사용률, 처리량을 최대화
처리 시간, 대기 시간, 응답 시간을 최소화 - SJF(Shortest Job First)
CPU 버스트 시간이 가장 짧은 프로세스에 CPU를 할당 - Round Robin
각 프로세스는 시간 퀀텀이라는 작은 CPU 시간 단위 - Multilevel Feedback Queues
프로세스는 다양한 대기열 사이를 이동
'운영체제' 카테고리의 다른 글
| [OS] 교착상태(Deadlocks) (0) | 2023.04.17 |
|---|---|
| [OS] 동기화 도구 (0) | 2023.04.03 |
| [OS] 쓰레드와 프로세스 (0) | 2023.03.20 |
| [OS] 프로세스 (0) | 2023.03.13 |
| [OS] 서비스, 시스템 콜, 구조, 부팅 과정 (0) | 2023.03.09 |